
How can economies forget? How is it that once we have learned to do something better, that knowledge can be lost and economies move backward? How can productivity decline? Viewing productivity as knowledge, it would seem almost impossible for it to do so -- and real business cycle theory was often derided on that point. Yet middle ages eurpoeans lost the recipe for concrete, and time after time we have seen economies get worse. How can our own productivity be growing so slowly overall when so much we see around us is progressing so fast?
Scott Alexander at Slate Star Codex has an intriguing blog post that illuminates these questions (HT marginal revolution). I'll offer my thoughts on the answers at the end.
Scott starts with education:
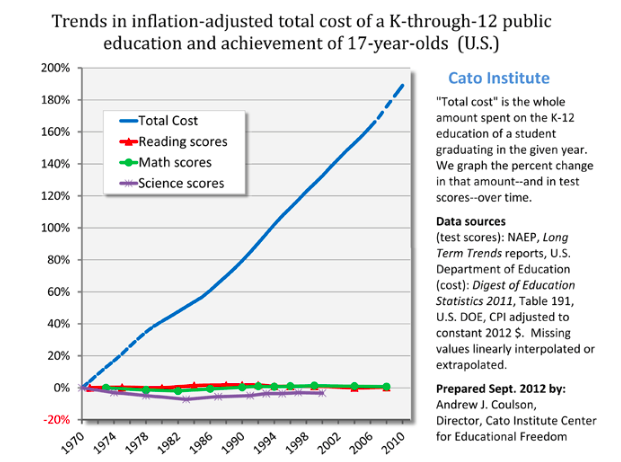 Inputs triple, output unchanged. Productivity dropped to a third of its previous level.
Inputs triple, output unchanged. Productivity dropped to a third of its previous level.
Scott offers remarkable economic clarity on the issue:
Infrastructure, today's cause célèbre is more telling,
I find this one particularly telling, because we're building 19th century technology, with 21st century tools -- huge boring machines that dramatically cut costs. And other countries still know how to do it for costs orders of magnitude lower than ours.
Similarly, housing. bottom line
More useful anectdotes, on whether this is real or just a figment of statistics.
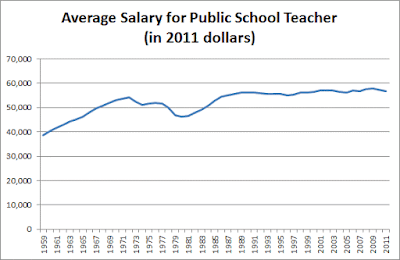
Scott has similar evidence for college professors, doctors, nurses and so on. What about fancy salaries you hear about?
Scott's elegant summary:
I think Scott's post is exceptionally good because it points out the enormous size of the problem. It's just not salient to point to productivity numbers that grow a few percentage points higher or lower. When you add it up over decades to see that while some things have gotten ten times better, other things are ten times more expensive than they should be really strikes home.
Scott tries on a list of candidate explanations and doesn't really find any. He comes closest with regulation, but correctly points out that formal regulatory requirements, though getting a lot worse, don't add up to the huge size of this cost disease.
So, what is really happening? I think Scott nearly gets there. Things cost 10 times as much, 10 times more than they used to and 10 times more than in other countries. It's not going to wages. It's not going to profits. So where is it going?
The unavoidable answer: The number of people it takes to produce these goods is skyrocketing. Labor productivity -- number of people per quality adjusted output -- declined by a factor of 10 in these areas. It pretty much has to be that: if the money is not going to profits, to to each employee, it must be going to the number of employees.
How can that happen? Our machines are better than ever, as Scott points out. Well, we (and especially we economists) pay too much attention to snazzy gadgets. Productivity depends on organizations not just on gadgets. Southwest figured out how to turn an airplane around in 20 minutes, and it still takes United an hour.
Contrariwise, I think we know where the extra people are. The ratio of teachers to students hasn't gone down a lot -- but the ratio of administrators to students has shot up. Most large public school systems spend more than half their budget on administrators. Similarly, class sizes at most colleges and universities haven't changed that much -- but administrative staff have exploded. There are 2.5 people handling insurance claims for every doctor. Construction sites have always had a lot of people standing around for every one actually working the machine. But now for every person operating the machine there is an army of planners, regulators, lawyers, administrative staff, consultants and so on. (I welcome pointers to good graphs and numbers on this sort of thing.)
So, my bottom line: administrative bloat.
Well, how does bloat come about? Regulations and law are, as Scott mentions, part of the problem. These are all areas either run by the government or with large government involvement. But the real key is, I think lack of competition. These are above all areas with not much competition. In turn, however, they are not by a long shot "natural monopolies" or failure of some free market. The main effect of our regulatory and legal system is not so much to directly raise costs, as it is to lessen competition (that is often its purpose). The lack of competition leads to the cost disease.
Though textbooks teach that monopoly leads to profits, it doesn't "The best of all monopoly profits is a quiet life" said Hicks. Everywhere we see businesses protected from competition, especially highly regulated businesses, we see the cost disease spreading. And it spreads largely by forcing companies to hire loads of useless people.
Yes, technical regress can happen. Productivity depends as much on the functioning of large organizations, and the overall legal and regulatory system in which they operate, as it does on gadgets. We can indeed "forget" how those work. Like our ancestors peer at the buildings, aqueducts, dams, roads, and bridges put up by our ancestors, whether Roman or American, and wonder just how they did it.
Scott Alexander at Slate Star Codex has an intriguing blog post that illuminates these questions (HT marginal revolution). I'll offer my thoughts on the answers at the end.
Scott starts with education:
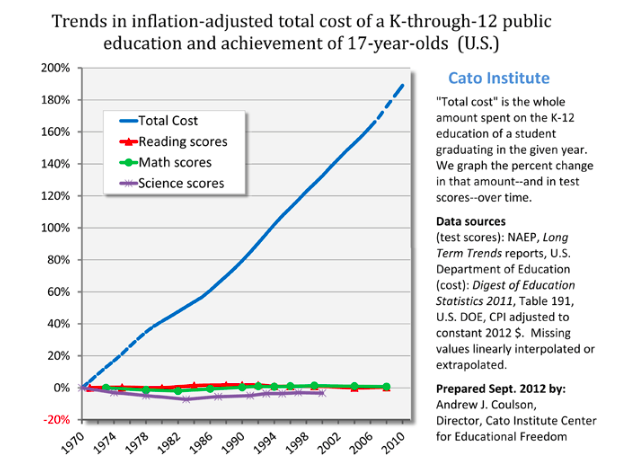
Scott offers remarkable economic clarity on the issue:
"Which would you prefer? Sending your child to a 2016 school? Or sending your child to a 1975 school, and getting a check for $5,000 every year?
I’m proposing that choice because as far as I can tell that is the stakes here. 2016 schools have whatever tiny test score advantage they have over 1975 schools, and cost $5000/year more, inflation adjusted. That $5000 comes out of the pocket of somebody – either taxpayers, or other people who could be helped by government programs.
...College is even worse. Inflation-adjusted cost of a university education was something like $2000/year in 1980. Now it’s closer to $20,000/year.... Do you think that modern colleges provide $18,000/year greater value than colleges did in your parents’ day? Would you rather graduate from a modern college, or graduate from a college more like the one your parents went to, plus get a check for $72,000? (or, more realistically, have $72,000 less in student loans to pay off)"Health care is similarly bloated, though a more complex case.
The cost of health care has about quintupled since 1970. ... The average 1960 worker spent ten days’ worth of their yearly paycheck on health insurance; the average modern worker spends sixty days’ worth of it, a sixth of their entire earnings.Unlike schooling, health care is unquestionably better now. Scott notices that lifespan doesn't go up as much as we might have hoped, and other countries get the same lifespan with much less cost. Tell that to someone with an advanced cancer, curable with modern drugs and not with 1970 drugs. Still, it's a good example to keep in mind, as it's pretty clear health care is delivering a technologically more advanced product with a huge decrease in organizational efficiency.
Infrastructure, today's cause célèbre is more telling,
"The first New York City subway opened around 1900. ...That looks like it’s about the inflation-adjusted equivalent of $100 million/kilometer today... In contrast, Vox notes [JC: This is an excellent article worth a blog post on its own] that a new New York subway line being opened this year costs about $2.2 billion per kilometer, suggesting a cost increase of twenty times – although I’m very uncertain about this estimate.
...The same Vox article notes that Paris, Berlin, and Copenhagen subways cost about $250 million per kilometer, almost 90% less. Yet even those European subways are overpriced compared to Korea, where a kilometer of subway in Seoul costs $40 million/km (another Korean subway project cost $80 million/km). This is a difference of 50x between Seoul and New York for apparently comparable services. It suggests that the 1900s New York estimate above may have been roughly accurate if their efficiency was roughly in line with that of modern Europe and Korea."I have seen similar numbers for high speed trains -- ours cost multiples of France's, let alone China's.
I find this one particularly telling, because we're building 19th century technology, with 21st century tools -- huge boring machines that dramatically cut costs. And other countries still know how to do it for costs orders of magnitude lower than ours.
Similarly, housing. bottom line
"Or, once again, just ask yourself: do you think most poor and middle class people would rather:Housing is a little different I think, because much of the cost rise is the value of land, so supply restrictions are clearly at work.
1. Rent a modern house/apartment
2. Rent the sort of house/apartment their parents had, for half the cost"
More useful anectdotes, on whether this is real or just a figment of statistics.
The last time I talked about this problem, someone mentioned they’re running a private school which does just as well as public schools but costs only $3000/student/year, a fourth of the usual rate. Marginal Revolution notes that India has a private health system that delivers the same quality of care as its public system for a quarter of the cost. Whenever the same drug is provided by the official US health system and some kind of grey market supplement sort of thing, the grey market supplement costs between a fifth and a tenth as much; for example, Google’s first hit for Deplin®, official prescription L-methylfolate, costs $175 for a month’s supply; unregulated L-methylfolate supplement delivers the same dose for about $30. And this isn’t even mentioning things like the $1 bag of saline that costs $700 at hospitals.Where is the money going? It's not, despite what you may think, going to higher salaries:
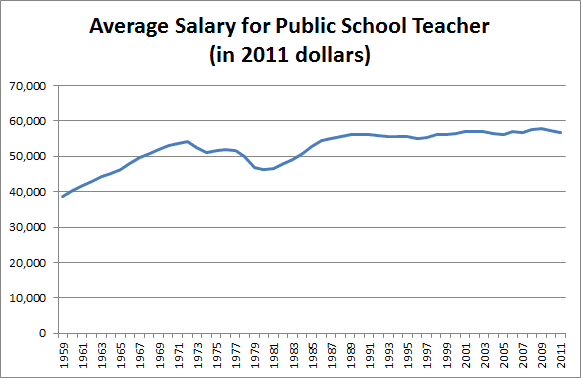
Scott has similar evidence for college professors, doctors, nurses and so on. What about fancy salaries you hear about?
...colleges are doing everything they can to switch from tenured professors to adjuncts, who complain of being overworked and abused while making about the same amount as a Starbucks barista.It's also not going to profits, or CEO salaries. Those have not risen by the orders of magnitude necessary to explain the cost disease.
This can’t be pure price-gouging, since corporate profits haven’t increased nearly enough to be where all the money is going.My thoughts below.
Scott's elegant summary:
So, to summarize: in the past fifty years, education costs have doubled, college costs have dectupled, health insurance costs have dectupled, subway costs have at least dectupled, and housing costs have increased by about fifty percent. US health care costs about four times as much as equivalent health care in other First World countries; US subways cost about eight times as much as equivalent subways in other First World countries.Scott points out that many of our intractable political debates -- paying for college, health care, housing, and transportation, are made intractable by this bloat:
And this is especially strange because we expect that improving technology and globalization ought to cut costs. In 1983, the first mobile phone cost $4,000 – about $10,000 in today’s dollars. It was also a gigantic piece of crap. Today you can get a much better phone for $100. This is the right and proper way of the universe. It’s why we fund scientists, and pay businesspeople the big bucks.
But things like college and health care have still had their prices dectuple. Patients can now schedule their appointments online; doctors can send prescriptions through the fax, pharmacies can keep track of medication histories on centralized computer systems that interface with the cloud, nurses get automatic reminders when they’re giving two drugs with a potential interaction, insurance companies accept payment through credit cards – and all of this costs ten times as much as it did in the days of punch cards and secretaries who did calculations by hand.
It’s actually even worse than this, because we take so many opportunities to save money that were unavailable in past generations. Underpaid foreign nurses immigrate to America and work for a song. Doctors’ notes are sent to India overnight where they’re transcribed by sweatshop-style labor for pennies an hour. Medical equipment gets manufactured in goodness-only-knows which obscure Third World country. And it still costs ten times as much as when this was all made in the USA – and that back when minimum wages were proportionally higher than today.
And it’s actually even worse than this. A lot of these services have decreased in quality, presumably as an attempt to cut costs even further. Doctors used to make house calls; even when I was young in the ’80s my father would still go to the houses of difficult patients who were too sick to come to his office. This study notes that for women who give birth in the hospital, “the standard length of stay was 8 to 14 days in the 1950s but declined to less than 2 days in the mid-1990s”. The doctors I talk to say this isn’t because modern women are healthier, it’s because they kick them out as soon as it’s safe to free up beds for the next person. Historic records of hospital care generally describe leisurely convalescence periods and making sure somebody felt absolutely well before letting them go; this seems bizarre to anyone who has participated in a modern hospital, where the mantra is to kick people out as soon as they’re “stable” ie not in acute crisis.
If we had to provide the same quality of service as we did in 1960, and without the gains from modern technology and globalization, who even knows how many times more health care would cost? Fifty times more? A hundred times more?
And the same is true for colleges and houses and subways and so on.
I don’t know why more people don’t just come out and say “LOOK, REALLY OUR MAIN PROBLEM IS THAT ALL THE MOST IMPORTANT THINGS COST TEN TIMES AS MUCH AS THEY USED TO FOR NO REASON, PLUS THEY SEEM TO BE GOING DOWN IN QUALITY, AND NOBODY KNOWS WHY, AND WE’RE MOSTLY JUST DESPERATELY FLAILING AROUND LOOKING FOR SOLUTIONS HERE.” State that clearly, and a lot of political debates take on a different light.What's happening?
I think Scott's post is exceptionally good because it points out the enormous size of the problem. It's just not salient to point to productivity numbers that grow a few percentage points higher or lower. When you add it up over decades to see that while some things have gotten ten times better, other things are ten times more expensive than they should be really strikes home.
Scott tries on a list of candidate explanations and doesn't really find any. He comes closest with regulation, but correctly points out that formal regulatory requirements, though getting a lot worse, don't add up to the huge size of this cost disease.
So, what is really happening? I think Scott nearly gets there. Things cost 10 times as much, 10 times more than they used to and 10 times more than in other countries. It's not going to wages. It's not going to profits. So where is it going?
The unavoidable answer: The number of people it takes to produce these goods is skyrocketing. Labor productivity -- number of people per quality adjusted output -- declined by a factor of 10 in these areas. It pretty much has to be that: if the money is not going to profits, to to each employee, it must be going to the number of employees.
How can that happen? Our machines are better than ever, as Scott points out. Well, we (and especially we economists) pay too much attention to snazzy gadgets. Productivity depends on organizations not just on gadgets. Southwest figured out how to turn an airplane around in 20 minutes, and it still takes United an hour.
Contrariwise, I think we know where the extra people are. The ratio of teachers to students hasn't gone down a lot -- but the ratio of administrators to students has shot up. Most large public school systems spend more than half their budget on administrators. Similarly, class sizes at most colleges and universities haven't changed that much -- but administrative staff have exploded. There are 2.5 people handling insurance claims for every doctor. Construction sites have always had a lot of people standing around for every one actually working the machine. But now for every person operating the machine there is an army of planners, regulators, lawyers, administrative staff, consultants and so on. (I welcome pointers to good graphs and numbers on this sort of thing.)
So, my bottom line: administrative bloat.
Well, how does bloat come about? Regulations and law are, as Scott mentions, part of the problem. These are all areas either run by the government or with large government involvement. But the real key is, I think lack of competition. These are above all areas with not much competition. In turn, however, they are not by a long shot "natural monopolies" or failure of some free market. The main effect of our regulatory and legal system is not so much to directly raise costs, as it is to lessen competition (that is often its purpose). The lack of competition leads to the cost disease.
Though textbooks teach that monopoly leads to profits, it doesn't "The best of all monopoly profits is a quiet life" said Hicks. Everywhere we see businesses protected from competition, especially highly regulated businesses, we see the cost disease spreading. And it spreads largely by forcing companies to hire loads of useless people.
Yes, technical regress can happen. Productivity depends as much on the functioning of large organizations, and the overall legal and regulatory system in which they operate, as it does on gadgets. We can indeed "forget" how those work. Like our ancestors peer at the buildings, aqueducts, dams, roads, and bridges put up by our ancestors, whether Roman or American, and wonder just how they did it.

 In Florida, a panel appointed by the Fish and Wildlife Conservation Commission is considering whether to recommend that canoes, kayaks, and other water craft that
In Florida, a panel appointed by the Fish and Wildlife Conservation Commission is considering whether to recommend that canoes, kayaks, and other water craft that 

